Z.ai 于 6 月 16 日放弃了 GLM-5.2,承诺提供顶级性能,击败其已经先进的 GLM 5.1。
这家位于北京的实验室自 2025 年 1 月起就被列入美国实体名单,它似乎受益于人们对美国人工智能方式日益增长的担忧。过去一周,《人间寓言》的封禁以及这款新机型的发布,带动zAI的股价上涨90%,创下历史新高。
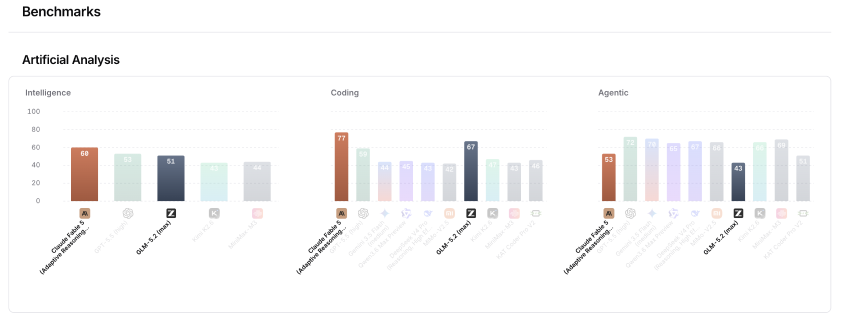
GLM 5.2 有数据支持这一炒作。
FrontierSWE 是一个评估 AI 代理能否完成以小时为单位的开放式技术项目的基准,涵盖系统优化、大规模代码构建和应用机器学习研究,按主导率评分 - GLM-5.2 达到 74.4,而 Claude Opus 4.8 为 75.1。它以 72.6 的成绩击败了 GPT-5.5。在 SWE-bench Pro(测试自动解决现实世界 GitHub 问题的通过率)上,GLM-5.2 的得分为 62.1,而 GPT-5.5 的得分为 58.6,并且大幅超越了其前身 GLM-5.1 的 58.4。
质量的飞跃使其成为人工智能分析智能指数中迄今为止最好的开源模型,该指数汇总了 9 个不同分数的结果来评估人工智能模型的总体质量。 OpenRouter 的基准测试将其与现已被禁止的 Claude Fable 5 归为同一类别。
用于实现这一壮举的硬件是故事的另一个有趣的部分。 GLM-5.2 在华为 Ascend 芯片上进行训练——管道中没有任何 Nvidia 芯片。 Stability AI 创始人 Emad Mostaque 估计总培训成本约为 2500 万美元,其中 80% 是后期培训,这使得与同行相比极其便宜。
正如Decrypt 今年早些时候报道的,Z.ai 已经在华为的 Ascend Atlas 服务器上训练图像模型,而没有使用任何美国芯片。 GLM-5.2 进一步发展了该基础设施——一个包含 7440 亿个参数的专家混合模型,具有真正的 100 万个令牌上下文窗口,是 GLM-5.1 20 万个限制的五倍,并且拥有 MIT 许可证,这意味着任何政府指令都无法翻转访问开关。
令牌是模型可以读取和生成的 tet 块,而参数是确定模型如何处理信息和生成响应的内部设置和值的数量
它的用途和费用
对于开发人员来说,上下文窗口是操作转变。以前需要分块的整个存储库导航、多文件重构和长代理管道变成了单调用工作流程。 API 定价为每百万输入代币 1.40 美元,每百万输出代币 4.40 美元,而 Claude Opus 4.8 的输入为 5 美元,输出为 25 美元。编码计划起价约为每月 18 美元,可直接在 Claude Code、Cline、Kilo Code 和最流行的代理环境中运行。
本地部署在技术上也是可行的。 Unsloth AI 推动了 2 位 GGUF 量化,将模型从 1.51TB 压缩到 238GB,同时保持约 82% 的准确度。
不过,别太兴奋。这仍然意味着它需要 256GB 统一内存或匹配的 RAM/VRAM 组合 - 一个最大的 M4 Ultra Mac Studio 或具有中档 GPU 和 256GB 系统 RAM 并具有混合专家卸载功能的工作站。这仍然是一大笔钱,但至少是你可以购买并在你的房子上运行的东西,如果你真的愿意的话。
我们进行了快速测试,要求 GLM-5.2 构建我们的标准游戏,混合打字机制和射击游戏。用户界面并不是最漂亮的——其他模型生成了更美观的界面,但体验却是最多样化的:不同的场景跨越波次,敌人类型发生变化,boss 在游戏后期出现。
它生成的游戏状态比我们在零镜头设置中针对同一任务测试的任何其他游戏状态都更加多样化。
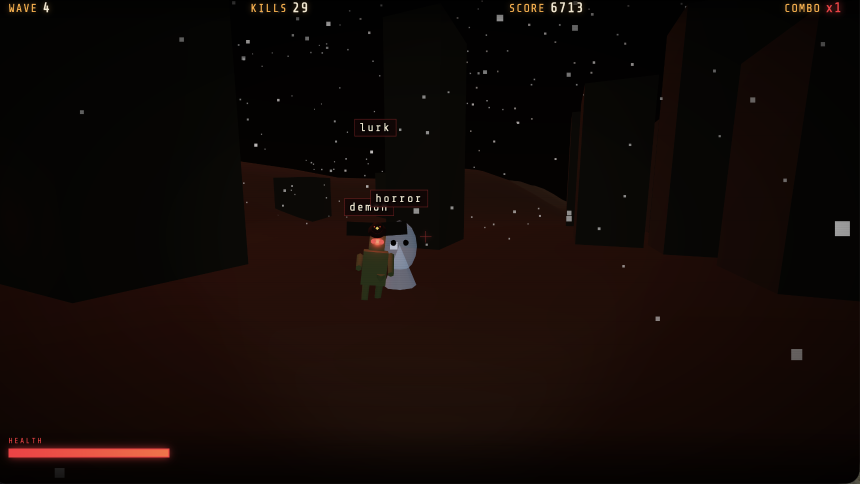
如果您想玩它,它就在我们的 Itch.io 个人资料中。
这种差异表明 GLM-5.2 最具经济意义。对于输出多样性比修饰更重要的多镜头生成工作流程和代理管道,开源定价水平的数学计算很难争论。对于最难的持续任务——SWE-马拉松,它的得分为 13.0,而 Opus 4.8 的得分为 26.0——与封闭边界的差距仍然是真实的,并且相差 13 分。
开源权重在 MIT 许可下在 HuggingFace 上上线。量化权重也可以在 HuggingFace 上找到。 GLM 编码计划订阅者现在可以使用模型字符串 GLM-5.2 进行切换,并且还可以在 z.AI 上进行免费测试,但有一些使用限制。